Tag: efficient frontier
-
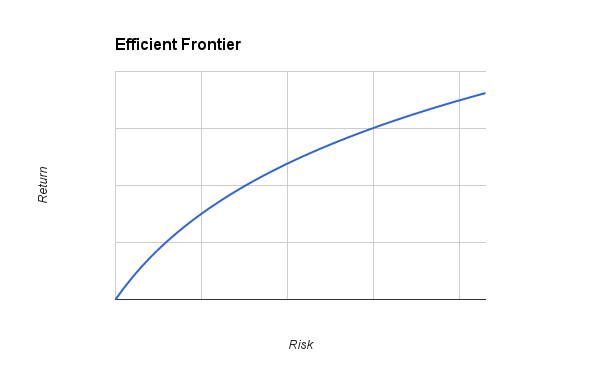
Computational Finance – Portfolio Optimization
I’ve been studying a Computational Finance module for the past few months now, and it’s absolutely fascinating. This blog post focuses on Markowitz Portfolio Optimization (AKA Modern portfolio theory), and will be part of a number of Computational Finance posts I’ll be posting over the coming months. The following post includes MATLAB examples, but these could be…